 OCR Pages
OCR Pages
Click OCR Pages to perform optical character recognition on documents:
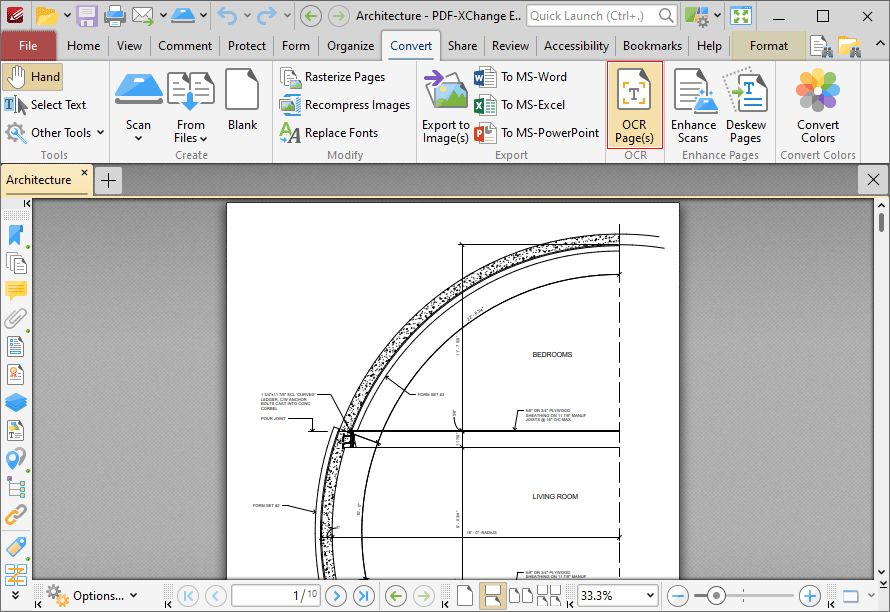
Figure 1. Convert Tab, OCR Pages
Note that two optical character recognition engines are available in PDF-Exchange Editor: the Default OCR engine and the Enhanced OCR engine, which is available when PDF-Exchange Editor Plus is purchased (either as a stand-alone product or as part of the PDF-XChange PRO bundle). The Enhanced OCR engine is faster, more accurate and more dynamic than the default OCR engine, and it also contains some extra features. Further information about the Enhanced OCR engine is available here. You can use the OCR Preferences (available via the Preferences option in the File tab) to switch between default and enhanced OCR:
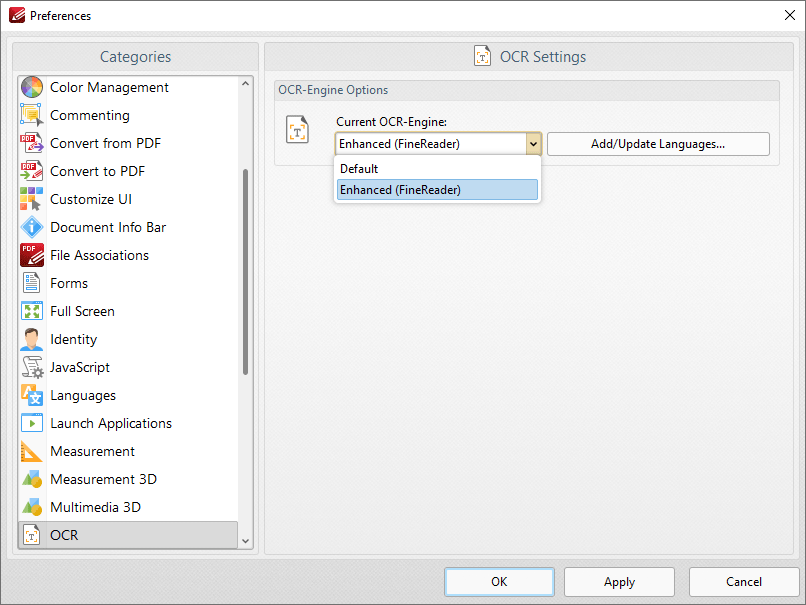
Figure 2. Preferences Dialog Box, OCR Category, OCR Engine Dropdown Menu
Default OCR Engine
The default engine's OCR process in PDF-XChange Editor analyzes image-based documents, recognizes text and then places a duplicate, invisible text layer on top of it, which makes the source text selectable and searchable in the same manner as ordinary text. When this option is selected the OCR Pages dialog box will open:
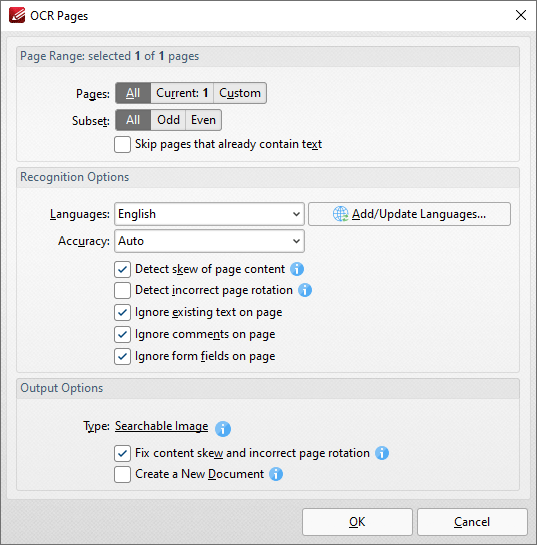
Figure 3. OCR Pages Dialog Box
Use the Page Range settings to determine the page range for OCR:
•Select All to specify all pages.
•Select Current to specify only the current page.
•Select Custom to specify a custom page range, then enter the desired page range in the adjacent number box. Further information about how to specify custom page ranges is available here.
•Use the Subset options to specify a subset of selected pages. Select All, Odd or Even as desired.
Use the Recognition Options to determine the language and accuracy of the OCR process. Please note that increasing the accuracy also increases the time that the process takes and vice versa. Additionally, it should be noted that setting the accuracy to high may result in unusual output if the document contains imperfections. This is because the software will search to a greater depth and may attempt to recognize imperfections as text. Click Add/Update Languages to add/update the language packs used for OCR.
•Select the Detect skew of page content box to enable automatic detection of skewed pages, which happens when documents are scanned crookedly.
•Select the Detect incorrect page rotation box to enable the automatic detection of incorrect page rotation in documents.
•Select the Ignore existing text on page box to omit existing text from the process of optical character recognition.
•Select the Ignore comments on page box to omit comments from the process of optical character recognition.
•Select the Ignore form fields on page box to omit form fields from the process of optical character recognition.
Use the Output Options to determine the format and quality of output from the OCR process:
•Select the Fix content skew and incorrect page rotation box to deskew pages that are scanned crookedly and auto-correct page rotation issues.
•Select the Create a New Document box to create a new document for the output of the optical character recognition. If this box is not selected, then the original document will be updated with the output instead.
Click OK to OCR documents.
Enhanced OCR Engine
The Enhanced OCR dialog box appears as detailed below:
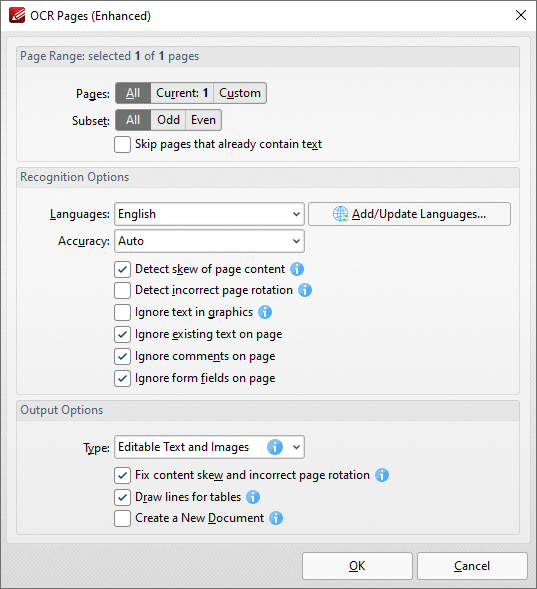
Figure 4. OCR Pages (Enhanced) Dialog Box
The options in this dialog box are the same as those detailed in (figure 3) but with additional Output Options:
•Select Searchable Image to retain the image-based content on which OCR is performed and insert a duplicate, invisible text layer on the text recognized during the operation. This will make the source text selectable and searchable in the same manner as ordinary text.
•Select Editable Text and Images to replace image-based text in source documents with the text recognized in the process of optical character recognition. This will convert image-based text into editable text, and retain existing content such as text and images.
•Select Fine Page Content to replace the content of source documents with new content that contains only the text and images recognized during optical character recognition.
•Select the Draw Lines for tables box to replace recognized column/row lines in tables with editable vector lines in output documents.
Please note that in some cases (for example documents that contain one large graphic zone that takes up the whole page area and has some text zones over it) the visual output for Editable Text and Images and Fine Page Content will be very similar.
Click OK to OCR documents.
OCR Selected Region
It is also possible to perform OCR on selected regions of documents. This is possible after either the Snapshot Tool or the Crop Page Tool has been used to define a page area, and the option is available in the right-click shortcut menu. For example, click Other Tools in the Organize tab, then click Snapshot Tool and click and drag the mouse to define a snapshot area:
Figure 5. Active Snapshot Tool
When the area has been defined, right-click it and then click OCR Selected Region in the shortcut menu:
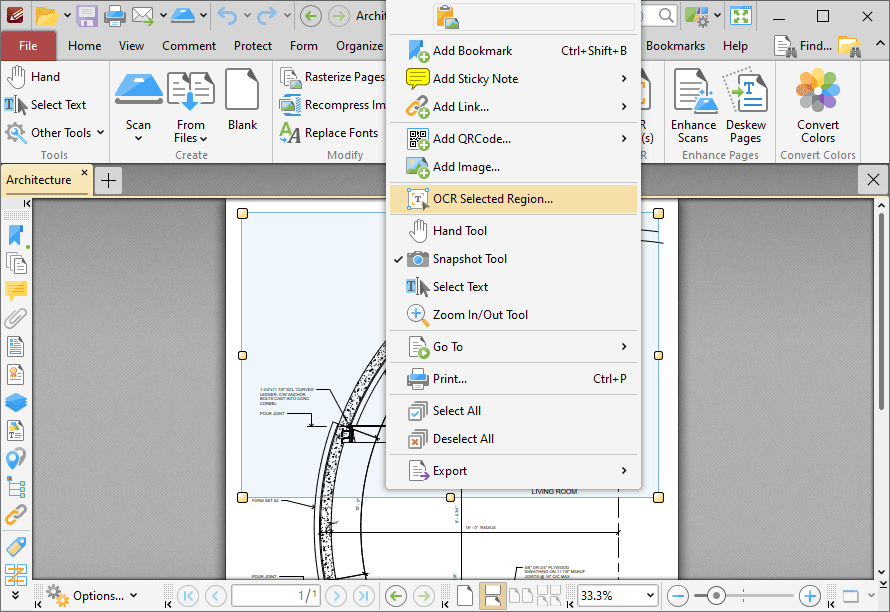
Figure 6. Right-Click Shortcut Menu, OCR Selected Region Highlighted
The OCR Options dialog box will open. Determine parameters as detailed above and then click OK to perform OCR on the selected region of the document.